In my daily job at Red Hat, I'm focused these days on making WildFly run great on container platforms such as Kubernetes.
"Traditional" way to develop and run applications with WildFly
WildFly is a "traditional" application server for Entreprise Java applications. To use it on the cloud, we are making it more flexible and closer to "cloud-native" applications so that it can be used to develop and run a 12-Factor App.
Traditionally, if you were using WildFly on your own machine, the (simplified) steps would be:
Download WildFly archive and unzip it
Edit its XML configuration to match your application requirements
In your code repository, build your deployment (WAR, EAR, etc.) with Maven
Start WildFly
Copy your deployment
Run tests
At this point, your application is verified and ready to use.
There are a few caveats to be mindful of.
Whenever a new version of WildFly is available, you have to re-apply your configuration change and verify that the resulting configuration is valid.
You run tests against your local download of WildFly with your local modifications. Are you sure that these changes are up to date with the production servers?
If you are developing multiple applications, are you using different WildFly downloads to test them separately?
"Cloudy" way to develop and run applications with WildFly
When you want to operate such application on the cloud, you want to automate all these steps in a reproduceable manner.
To achieve this, we inverted the traditional application server paradigm.
Before, WildFly was the top-level entity and you were deploying your applications (ie WARs and EARs) on it. Now, your application is the top-level entity and you are in control of the WildFly runtime.
With that new paradigm, the steps to use WildFly on the cloud are now:
In your code repository, configure WildFly runtime (using a Maven plugin)
Use Maven to build your application
Deploy your application in your target container platform
Step (2) is the key as it automates and centralizes most of the "plumbing" that was previously achieved by hand.
If we decompose this step, it actually achieves the following:
Compile your code and generate the deployment
"Provision" WildFly to download it, change its configuration to match the application requirements
deploy your deployment in the provisioned WildFly server
Run integration tests against the actual runtime (WildFly + your deployments) that will be used in production
Optionally create a container image using docker
Comparing the two ways to develop and run WildFly can look deceiving. However, a closer examination shows that the "Cloudy" way unlocks many improvements in terms of productivity, automation, testing and, at least in my opinion, developer joy.
What does WildFly provide for 12-Factor App development?
The key difference is that your Maven project (and its pom.xml) is the single 12-factor's Codebase to track your application. Everything (your application dependencies, WildFly version and configuration changes) is tracked in this repo. You are sure that what is built from this repository will always be consistent. You are also sure that WildFly configuration is up to date with production server because your project is where its configuration is updated. You are not at risk of deploying your WAR in a different version of the server or a server that has not been properly configured for your application.
Using the WildFly Maven Plugin to provision WildFly ensures that all your 12-factor's Dependencies are explicitly declared. Wheneve a new version of WildFly is released, you can be notified with something like Dependabot and automatically test your application with this new release.
Using the WildFly Maven Plugin in your pom.xml, you can simply have different stages to 12-factor's Build, release, run and make sure you build once your release artifact (the application image) and runs it on your container platform as needed.
Entreprise Java application as traditionally stateful so it does not adhere to the 12-factor's Processes unless you refactor your Java application to make it stateless.
WildFly complies with 12-factor's Port binding and you can rely on accessing its HTTP port on 8080 and its management interfance on 9990.
Scaling out your application to handle 12-factor's concurrency via the process model is depending on your application architecture. However WildFly can be provisioned in such a way that its runtime can exactly fit your application requirements and "trim" any capabilites that is not needed. You can also split a monolith Entreprise Java application in multiple applications to scale the parts that need it.
12-factor's Disposability is achieved by having WildFly fast booting time as well as graceful shutdown capabilities to let applications finish their tasks before shutting down.
12-factor's Dev/prod parity is enabled when we are able to use continuous deployment and having a single codebase to keep the gap between what we develop and what we operate. Using WildFly with container-based testing tool (such as Testcontainers) ensures that what we test is very similar (if not identical) to what is operated.
WildFly has extensive logging capabilities (for its own runtime as well as your application code) and works out of the bow with 12-factor's Logs by outputting its content on the standard output. For advanced use cases, you can change its output to use a JSON formatter to query and monitor its logs.
12-factor's Admin processes has been there from the start with WildFly that provides a extensive CLI tool to run management operations on a server (running or not). The same management operations can be executed when WildFly is provisioned by the WildFly Maven Plugin to adapt its configuration to your application.
Summary
We can develop and operate Entrprise Java applications with a modern software methodology. Some of these principles resonate more if you targeting cloud environment but most of them are still beneficical for traditional "bare metal" deployments.
With a single mvn package, you can build your release artifact and deploy it wherever you want. The WildFly Maven Plugin can generate ate a directory or an application image to suit either bare-metal or container-based platform.
Entreprise Java application have traditionally be scaling up so there is some architecture and application changes to make them scale out instead. The lightweight runtime from WildFly is definitely a good opportunity for scaling out Entreprise Java applications.
Use the WildFly Maven Plugin to control WildFly, container-based testing to reduce the integration disparity and keep changes between dev, staging and production to a minimum.
WildFly tooling provides CLI scripts to run management operations. You can store them in your codebase to handle configuration changes, migration operations, maintenance operations.
Conclusion
Using the "cloudy" way to develop and operate entreprise applications unlocks many benefits regardless of the deployment platform (container-based or bare metal).
It can automate most of the mundane tasks that reduce developer joy & efficiency while improving the running operations of WildFly improving operator joy & efficiency.
Web browers now treats sites served by HTTP as "Not secure". I finally caved in and added a TLS certificate to jmesnil.net.
Displayed Padlock achievement: completed
If you are visiting jmesnil.net, you can now browse it safely and be sure that your credit cards numbers will not be stolen. That's progress I suppose...
I host my site on Amazon AWS and use a bunch of their services (S3, Route 53, CloudFront, Certificate Manager) to be able to redirect the HTTP traffic to HTTPS (and the www.jmesnil.net URLs to jmesnil.net). I will see how much this increase the AWS bill...
More interestingly, I used Let's Encrypt to generate the certificates. It took me less than 5 minutes to generate it (including the acme challenge to verify the ownership of the jmesnil.net domain name). This project is a great example of simplifying and making accessible a complex technology to web publishers.
On October 17th of last year, while playing basketball, I suffered a ruptured Achilles tendon.
Unfortunately, an initial misdiagnosis and a lengthy waitlist for necessary medical examinations resulted in me having to postpone surgery until December 9th. The tendon rupture measured approximately 6cm, necessitating the use of tissue from adjacent areas of my feet to construct a completely new tendon.
This led to a period of immobilization lasting 45 days. Although the Christmas break was not particularly enjoyable, I consider myself fortunate to have an incredible wife and children who provided unwavering support, showering me with love and kindness throughout the ordeal. My managers and colleagues at Red Hat were also very supportive so that I could focus on my health during that period.
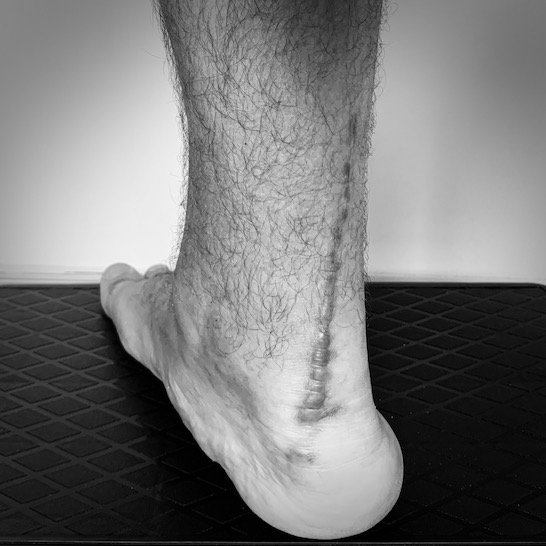
When my boot was finally removed, I caught sight of my foot for the first time, revealing a 15cm scar that I could proudly boast about if I were on the "Jaws" boat :)
By the end of January, I cautiously began walking again, albeit with a noticeable limp. Since then, my rehabilitation has been a gradual journey with its fair share of ups and downs. Yesterday, I was able to run 5 km, but today climbing stairs causes discomfort. I am hopeful that I will achieve a full recovery. As a symbolic "endpoint" to my rehab, I have set a goal to participate in a semi-marathon next year.
Although my competitive basketball days are over, I am still enthusiastic about playing with my kids and continuing to enjoy the sport. I'll play it less and watch it more :) Walking, running, and hiking at my own pace have become my main physical activities, whether I'm by myself or accompanied by friends and family. They provide me energy, focus and a deep appreciation of a functional body.
Holly Cummins, a colleague at Red Hat and Java Champion, is making a lot of great content about making software greener.
Her presentation focuses on Quarkus which is a greenfield1 Java framework focused on Cloud-native applications while my job is on WildFly and JBoss EAP, Java application servers that predate the Cloud.
Her presentation resonates with me professionally and personally.
Professionally, my focus these days is on making WildFly and EAP run great on the Cloud. Doing so in a sustainable manner is important as it has direct impact on our users' costs and performance.
Personally, and more importantly, it resonates with my vision of my work and my life. All my career has been done around Open Source projects. They fit my idea of a good humane society with core values of Openness, Meritocracy and Accountability. Developping Open Source code is now a given for me and I don't envision other ways to perform my job.
The next frontier is now to develop Sustainable code that reduces our impact on the planet. I deeply believe now that any advancements we are making, whether it's the Cloud, Cryptocurrency, Machine-Learning, can not be at the expense at the planet and our future generations.
It's not simple to see how that translates in my daily tasks but we are past the point where we should include sustainability into our guiding principles and I'm making a deliberate conscious choice to do that now at my own level.
It is quite a milestone as it is the first specification released by the Eclipse MicroProfile project. It covers a simple need: unify the configuration of Java application from various sources with a simple API:
@Inject
@ConfigProperty(name = "app.timeout", defaultValue = "5000")
long timeout;
The developer no longer needs to check for configuration files, System properties, etc. He or she just specifies the name of the configuration property (and an optional default value). The Eclipse MicroProfile Config specification ensures that several sources will be queried in a consistent order to find the most relevant value for the property.
This implementation passes the MicroProfile Config 1.0 TCK. It can be used by any CDI-aware container/server (i.e. that are able to load CDI extensions).
This project also contains a WildFly extension so that any application deployed in WildFly can use the MicroProfile Config API. The microprofile-config subsystem can be used to configure various config sources such as directory-based for OpenShift/Kubernetes config maps (as described in a previous post) or the properties can be stored in the microprofile-config subsystem itself):
Finally, a Fraction is available for WildFly Swarm so that any Swarm application can use the Config API as long as it depends on the appropriate Maven artifact:
It is planned that this org.wildfly.swarm:microprofile-config Fraction will eventually move to Swarm own Git repository so that it Swarm will be able to autodetect applications using the Config API and load the dependency automatically. But, for the time being, the dependency must be added explicitely.
If you have any issues or enhancements you want to propose for the WildFly MicroProfile Config implementation, do not hesitate to open issues or propose contributions for it.
I recently looked at the Eclipse MicroProfile Healthcheck API to investigate its support in WildFly. WildFly Swarm is providing the sample implementation so I am very interested to make sure that WildFly and Swarm can both benefit from this specification.
This specification and its API are currently designed and anything written in this post will likely be obsolete when the final version is release. But without further ado...
Eclipse MicroProfile Healthcheck
The Eclipse MicroProfile Healthcheck is a specification to determine the healthiness of an application. It defines a HealthCheckProcedure interface that can be implemented by an application developer. It contains a single method that returns a HealthStatus: either UP or DOWN (plus some optional metadata relevant to the health check). Typically, an application would provide one or more health check procedures to check healthiness of its parts. The overall healthiness of the application is then determined by the aggregation of all the procedures provided by the application. If any procedure is DOWN, the overall outcome is DOWN. Else the application is considered as UP.
The specification has a companion document that specifies an HTTP endpoint and JSON format to check the healthiness of an application.
Using the HTTP endpoint, a container can ask the application whether it is healthy. If it is not healthy, the container can take actions to deal with it. It can decide to stop the application and eventually respin a new instance. The canonical example is Kubernetes that can configure a liveness probe to check this HTTP health URL (OpenShift also exposes this liveness probe).
WildFly Extension prototype
I have written a prototype of a WildFly extension to support health checks for applications deployed in WildFly and some provided directly by WildFly:
This HTTP endpoint can be used to configure OpenShift/Kubernetes liveness probe.
Any deployment that defines Health Check Procedures will have them registered to determine the overall healthiness of the process. The prototype has a simple example of a Web app that adds a health check procedure that randomly returns DOWN (which is not very useful ;).
WildFly Health Check Procedures
The Healthcheck specification mainly targets user applications that can apply application logic to determine their healthiness. However I wonder if we could reuse the concepts inside the application server (WildFly in my case). There are "things" that we could check to determine if the server runtime is healthy, e.g.:
The amount of heap memory is close to the max
some deployments have failed
Excessive GC
Running out of disk space
Some threads are deadlocked
These procedures are relevant regardless of the type of applications deployed on the server.
Subsystems inside WildFly could provide Health check procedures that would be queried to check the overall healthiness. We could for example provide a health check that the used heap memory is less that 90% of the max:
HealthCheck.install(context, "heap-memory", () -> {
MemoryMXBean memoryBean = ManagementFactory.getMemoryMXBean();
long memUsed = memoryBean.getHeapMemoryUsage().getUsed();
long memMax = memoryBean.getHeapMemoryUsage().getMax();
HealthResponse response = HealthResponse.named("heap-memory")
.withAttribute("used", memUsed)
.withAttribute("max", memMax);
// status is is down is used memory is greater than 90% of max memory.
HealthStatus status = (memUsed < memMax * 0.9) ? response.up() : response.down();
return status;
});
Summary
To better integrate WildFly with Cloud containers such as OpenShift (or Docker/Kunernetes), it should provide a way to let the container checks the healthiness of WildFly. The Healthcheck specification is a good candidate to provide such feature. It is worth exploring how we could leverage it for user deployments and also for WildFly internals (when that makes sense).
This post is about some updates of the project status and work being done to leverage the Config API in OpenShift (or other Docker/Kubernetes-based environment).
Project update
Since last post, WildFly and Swarm projects agreed to host the initial work I did in their GitHub projects and the Maven coordinates have been changed to reflect this. For the time being, everything is hosted at wildfly-extras/wildfly-microprofile-config.
The Eclipse MicroProfile Config 1.0 API should be released soon. Once it is released, we can then release the 1.0 version of the WildFly implementation and subsystem. The Swarm fraction will be moved to the Swarm own Git repo and will be available with future Swarm releases.
Until the Eclipse MicroProfile Config 1.0 API is released, you still have to build everything from wildfly-extras/wildfly-microprofile-config and uses the Maven coordinates:
We have added a new type of ConfigSource, DirConfigSource, that takes a File as a parameter.
When this ConfigSource is created, it scans the file (if that is a directory) and creates a property for each file in the directory. The key of the property is the name of the file and its value is the content of the file.
For example, if you create a directory named /etc/config/numbers-app and add a file in it named num.size with its content being 5, it can be used to configure the following property:
@Inject
@ConfigProperty(name = "num.size")
int numSize;
There are different ways to use the corresponding DirConfigSource depending on the type of applications.
WildFly Application
If you are deploying your application in WildFly, you can add this config source to the microprofile subsystem:
If you are using the WildFly implementation of the Config API outside of WildFly or Swarm, you can add it to a custom-made Config using the Eclipse MicroProfile ConfigBuilder API.
OpenShift/Kubernetes Config Maps
What is the use case for this new type of ConfigSource?
It maps to the concept of OpenShift/Kubernetes Config Maps so that an application that uses the Eclipse MicroProfile Config API can be deployed in a container and used its config maps as a source of its configuration.
I have added an OpenShift example that shows a simple Java application running in a variety of deployment and configuration use cases.
The application uses two properties to configure its behaviour. The application returns a list of random positive integers (the number of generated integers is controlled by the num.sizeproperty and their maximum value by the num.max property):
@Inject
@ConfigProperty(name = "num.size", defaultValue = "3")
int numSize;
@Inject
@ConfigProperty(name = "num.max", defaultValue = "" + Integer.MAX_VALUE)
int numMax;
The application can be run as a standalone Java application configured with System Properties:
This highlights the benefit of using the Eclipse MicroProfile Config API to configure a Java application: the application code remains simple and use the injected values from the Config API. The implementation then figures out all the sources where the values can come from (System properties, properties files, environment, and container config maps) and inject the appropriate ones.