Malin Space Science Systems' project manager Mike Ravin:
There's a popular belief that projects like this are going to be very advanced but there are things that mitigate against that. These designs were proposed in 2004, and you don't get to propose one specification and then go off and develop something else. 2MP with 8GB of flash [memory] didn't sound too bad in 2004. But it doesn't compare well to what you get in an iPhone today.
Did you notice something different on my Web site or my Atom feed? You shouldn't as I have successfully migrated from Jekyll to Awestruct.
A few months ago, I switched my Weblog from Wordpress to Jekyll because I wanted to have a simpler, slimmer publishing system that could generate a static Web site and be simple to customize. At first, Jekyll fit the bill nicely but as I was starting to tweak it, I was slowed down by its lack of documentation and customization. I want to be able to extend my publishing system, not fork it.
As an example of Awestruct extensibility, I wrote an extension to provide an Archive page for my Weblog. Awestruct defines an extension to create a weblog from a single directory with files matching the format of YYYY-MM-DD-post-title (like Jekyll does):
Awestruct::Extensions::Pipeline.new do
...
extension Awestruct::Extensions::Posts.new '/weblog', :posts
...
end
I wanted to add a page which lists all my posts sorted by ear and month. I added an extension to Awestruct pipeline for this:
Awestruct::Extensions::Pipeline.new do
...
extension Awestruct::Extensions::Posts.new '/weblog', :posts
extension Awestruct::Extensions::PostsArchiver.new '/weblog/archive', :posts, :archive
...
end
This extension takes the :posts that were added to the site by the Posts extension, sort them in a hierarchy of year / month / posts and put them in the variable named :archive that can be used inside the template file /weblog/archive (source code).
I could then have a very simple Haml template to display the archive:
---
layout: page
title : Archive
---
- site.archive.each do |year, monthly_archive|
%h2= year
- monthly_archive.each do |month, posts|
%h3= month
%ul
- posts.each do |post|
%li
= "#{post.date.strftime('%d %B %Y')} »"
- if post.link
%a.link{ :href=>post.url }= "#{site.linked_list.link} #{ post.title}"
- else
%a{ :href=>post.url }= post.title
In similar fashion, I have been able to add a Daring Fireball-style linked list to my Web site and Atom feed by simply adding a link metadata to the file front-matter and a few lines of HAM to process it.
I have been working on head scratching issues related to JMS ObjectMessage all week, ranting about it aloud, on IRC, in JIRA comments... Let's try to be constructive and address exactly why ObjectMessage is a bad idea and what should be used instead.
Stream - A StreamMessage object's message body contains a stream of primitive values in the Java programming language ("Java primitives"). It is filled and read sequentially. Map - A MapMessage object's message body contains a set of name-value pairs, where names are String objects, and values are Java primitives. The entries can be accessed sequentially or randomly by name. The order of the entries is undefined. Text - A TextMessage object's message body contains a java.lang.String object. This message type can be used to transport plain-text messages, and XML messages. Object - An ObjectMessage object's message body contains a Serializable Java object. Bytes - A BytesMessage object's message body contains a stream of uninterpreted bytes. This message type is for literally encoding a body to match an existing message format. In many cases, it is possible to use one of the other body types, which are easier to use. Although the JMS API allows the use of message properties with byte messages, they are typically not used, since the inclusion of properties may affect the format.
Of those five, only two are useful: Bytes and Text messages. The three others have their own issues1 but today's rant is about ObjectMessage.
Before analyzing ObjectMessage issues, let's see how it is used.
A Java client creates a ObjectMessage and set its body to a Serializable object (let's call it payload). It then sends it to a JMS Destination. The payload is sent over the wire as a stream of bytes. Note that the JMS API does not mandate how the payload can be serialized (it can be with standard Java serialization or something else).
Other Java clients (one if the destination is a queue, many if it is a topic) will receive this message with the serialized payload. They will call ObjectMessage.getObject() to retrieve the payload Java object. It is the responsibility of the messaging provider to deserialize the stream of bytes and reconstruct the payload object before passing it to the client.
Simple, isn't it? Not really.
Architectural Issues
One of the advantage of using messaging system is loose coupling. The producers and consumers of a destination does not need to know each other or be online at the same time to exchange messages. They only need to agree on the data sent in the message.
By using an ObjectMessage, the type of the Java object is their agreement. This means that both sides MUST be able to understand the object and its whole graph type. You are losing one degree of abstraction by using an ObjectMessage, the consumer(s) of this message must know the implementation type of the payload and have all the classes required to deserialize it. This introduces a strong coupling between producers and consumers since they now must share a common set of classes (which grows with the complexity of the payload type).
There is a simple solution to reduce this issue (but not removing it entirely): use DTO for ObjectMessage payload
Technical Issues
The technical issues of using ObjectMessage are related to the deserialization of the stream of bytes sent over the wire. To be able to deserialize an object, the messaging provider must be able to recreate the instance as it was when it was serialized. This also implies that we must have access to the same classes and classloader that were used to serialize the payload. My colleague, Jason Greene, has a nice article about modular serialization. Unfortunately, this is something more complex in our case since it is possible (and often the case!) that consumers of messages run in different environments than the producer.
As an example, we can have:
a Servlet that sends a message to a topic (its environment is a Java EE WAR module)
a MDB that consumes it (its environment is a Java EE EJB module)
a standalone Java application that also consumes it (its environment is a regular Java application)
Clients (1) and (2) will run in a modular application (e.g. JBoss AS7) while client (3) will run in a non-modular application (using regular Java classpath).
How can client (3) be expected to deserialize a class that was serialized in a different environment? Conversely if the client (1) use standard Java serialization, how can the client (2) be expected to deserialize it if it is not able to load all classes in the payload type (as modules does not export their dependencies)?
There is a simple solution to remove this issue:
Do not use ObjectMessage
Instead, define a data structure for the payload (using XML, JSON, protobuf, etc.) and use Text or Bytes message
Performance issues
How much space does it take to store a Java class with int and String fields as bytes instead of storing directly the int and the String?
It is not as simple to compare the size of a serialized Java object with the corresponding XML, JSON, protobuf payload. All these bytes are transported on the wire. The more bytes to serialize/transport/deserialize, the slower the message is delivered. (even though premature optimization is the root of all evil still prevails).
Conclusion
At first glance, ObjectMessage looks like a good idea. It lets application deals only with Java objects but it opens a whole can of architectural, technical and performance issues that will need to be dealt at one time or another, probably after the application is put in production...
I would suggest to reduce as much as possible the use of ObjectMessage (with the goal of getting rid of them completely) with 2 steps:
If possible, define a data representation for the payload (JSON, protobuf, XML) and use Text or Bytes message to carry it
It is not a huge task and your application will be all the better for it (loosely-coupled, resilient to changes, with explicit payload agreement, etc.)
For example, what if messages can also produced and consumed from non-Java applications using STOMP protocol? ↩
I am playing a bit with AS7 Management REST API and I want to display the full description of the server model from the Web browser.
Using the CLI, this is equivalent to
[standalone@localhost:9999 /] /:read-resource-description(recursive=true, operations=true)
{
"outcome" => "success",
"result" => {
"description" => "The root node of the server-level management model.",
"head-comment-allowed" => true,
"tail-comment-allowed" => true,
"attributes" => {
"namespaces" => {
"type" => OBJECT,
"value-type" => STRING,
"description" => "Map of namespaces used in the configuration XML document, where keys are namespace prefixes and values are schema URIs.",
"required" => false,
"head-comment-allowed" => false,
"tail-comment-allowed" => false,
"access-type" => "read-only",
"storage" => "configuration"
},
...
}
However, using the CLI is limiting for what I envision. The description that is returned is similar to JSON but it's not valid JSON. I want to interact with the descriptions using a programming language to iterate on resources, filter them out, etc.
The end game could be to generate a HTML documentation for each release of AS7 that could ship with the release and complement the existing documentation
To achieve this, I have first create a simple Sinatra application that queries a running AS7 server (in standalone mode) and display its resource description using the REST API.
The application is using Bundler to manage its dependencies through a Gemfile file:
We use Rack to start the Web server hosting our little app with a config.ru file:
require "./application.rb"
run Sinatra::Application
The application itsel if a simple Sinatra application which calls the AS7 management REST API (with authentication) and proxies the JSON output.
require 'rubygems'
require 'bundler/setup'
Bundler.require
get '/resource-description' do
user = params['user']
password = params['password']
return [500, "missing user and password parameters"] unless user and password
url = 'http://127.0.0.1:9990/management/'
operation = {:operation => "read-resource-description",
:recursive => params["recursive"] || false,
:operations => params["operations"] || false,
:inherited => params["inherited"] || false
}
res = AS7.query url, user, password, operation.to_json
if res.code == 200
[res.code, {'Content-type' => 'application/json'}, res.body.to_s]
else
[res.code, res.headers, res.body.to_s]
end
end
class AS7
include HTTParty
def AS7.query(url, user, password, operation)
digest_auth user, password
post url , :body => operation, :headers => {"Content-type" => "application/json"}
end
end
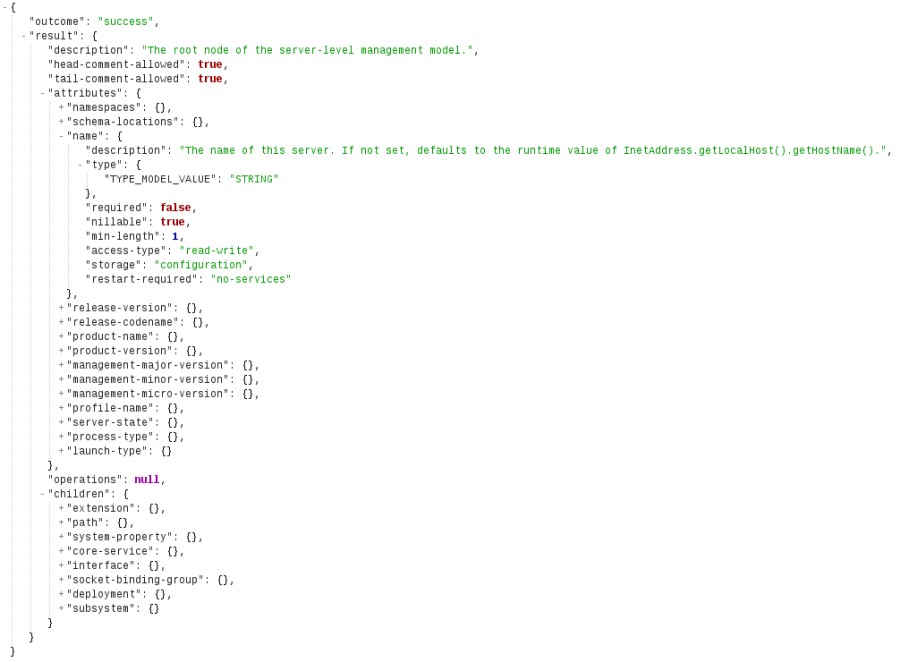
In itself, that's not terribly interesting but if it is coupled with a JSON prettifier extension, it displays a nice interactive JSON tree in the browser.
JSON output
To run the application:
$ bundle # to fetch the ruby gems
$ rackup config.ru
[2012-07-23 17:14:02] INFO WEBrick 1.3.1
[2012-07-23 17:14:02] INFO ruby 1.9.3 (2012-04-20) [x86_64-linux]
[2012-07-23 17:14:02] INFO WEBrick::HTTPServer#start: pid=11499 port=9292